前言
最近在学习python爬虫的scrapy框架,本文记录下遇到的问题和解决方案。
如果你不知道什么是scrapy,请移步:
正文
由于需要爬取大量的地址交易信息数据,如何保存这些数据是个很大的问题。
最开始我是这样的:
1 | with open('xxx.txt','a',encoding='utf-8') as fw: |
把全部数据都写入一个txt文件中,然后再复制到表格中去,现在想起来,好蠢!
后来我又学会了使用xlwt库,于是又变成了这样:
1 | import xlwt |
于是乎,是这样的:
用了一段时间xlwt后,遇到了一次超过65536行数据的情况,由于xlwt只能操作xls表格文件,xlwt就显得不够用了,一通搜索后,我换了openpyxl:
1 | from openpyxl import Workbook |
这下好了,xlsx最大能够存储1048576行数据,能够完全满足使用了,再大的数据量就得使用数据库了。
本来到这里也应该结束,本文也不该出现的。有天突(xian)发(de)奇(dan)想(teng),想着减少一下爬虫得代码量,正好scrapy本身也提供了item来接受数据,于是我改了下我的代码,把openpyxl代码全部删掉。
1 | #items.py |
换了这种方式后,代码看着一下就舒服多了(至于效率有没有提高,就不知道了,hahahaha~~)。
于是本篇文章正文来了:
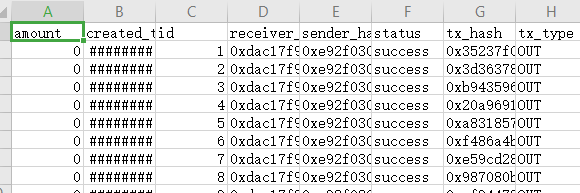
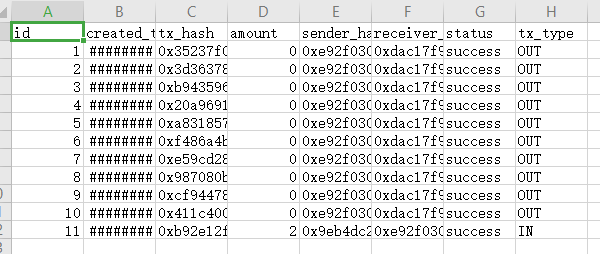
如上图所示,导出的csv文件内部title并不是我所期望的结果!
于是在Google上搜了搜:
这些文章里面大多都是使用的如下方式:
1 | #在scrapy的spiders同层目录,新建my_project_csv_item_exporter.py文件内容如下(文件名可改,目录定死) |
我照着他这个做了:
然鹅,引入都出现了问题,搜索之后发现 .conf以及.contrib已经在1.7.x版本中就废弃了,我用的是2.2.0版本,所以得使用其他得导入方式。
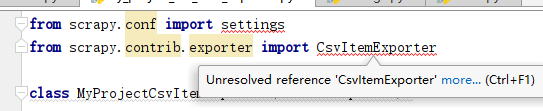
删除错误的导入后,利用pycharm的自带快速导入:
1 | from getAllTxs import settings |
然后又报错:
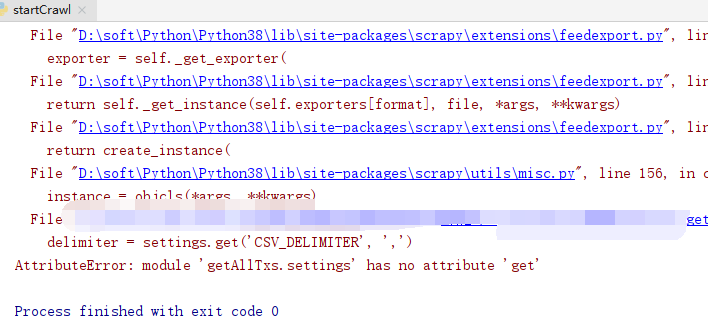
在新版 Scrapy 中 sys.conf.settings 的替代方法看到了解决方法:
1 | from scrapy.conf import settings |
然后,令人吃惊的事情发生了:
成功的按照自己想要的顺序写入了cvs文件中(写这篇文章之前,试了好多次都没成功,结果写文章的时候就好了!)。
因为最开始的时候,遇到了csv中顺序错误的问题,然后搜索了一堆解决方案也没有解决,我就放弃了上面的那种方式(谁知道它现在就好了!),找到了另一种更为简单的方式。
不得不说stack overflow真的是个好东西,以前好几次在其他地方找不到解决方法的问题,都是在上面得到了解决。
在How can I use the fields_to_export attribute in BaseItemExporter to order my Scrapy CSV data?这篇文章中使用了custom_settings的方式,在spider中进行定义,不需要额外的设置什么东西就能够让csv按照自己想要的顺序进行输出。
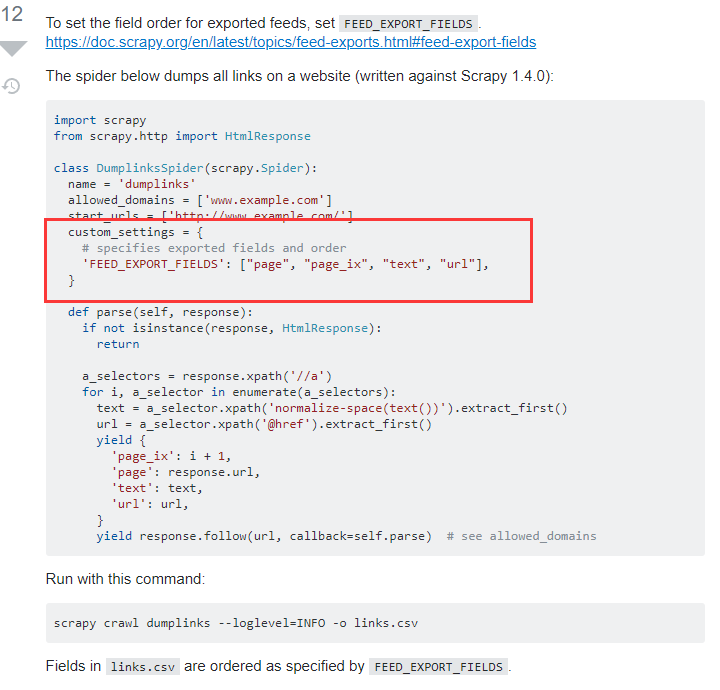
后记
至此,本文所描述的内容已经结束。通过本次问题的解决过程,发现了自己在进行实际操作的时候还是可能会遗漏些问题,以后还得更加细心啊。
完结★,°:.☆( ̄▽ ̄)/$:.°★ 。。